🔗 Research Paper
Description
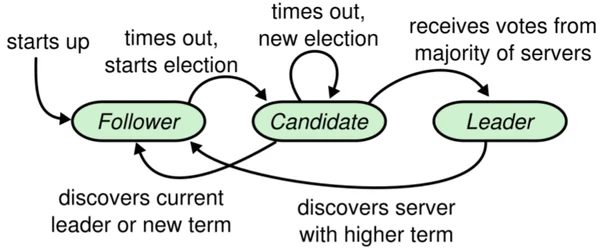
I developed a fault-tolerant and scalable key-value store using C++ that provides reliability through redundancy and distributed consensus. The project implements the Raft consensus algorithm to manage replicated operation logs across a cluster of servers. I programmed core Raft components like leader election, heartbeats, log replication, and recovery from failures. This allows the system to automatically elect a new leader if any server goes down.
On top of the replicated Raft log, I built a fast and scalable key-value storage service. Servers act as state machines, applying operations from the log to maintain an identical key-value database across the cluster. All data is replicated to multiple nodes for reliability. Reads and writes are handled through remote procedure calls (RPCs), facilitating horizontal scaling. The service is also persistence-based, saving the state machine data to disk for crash recovery.
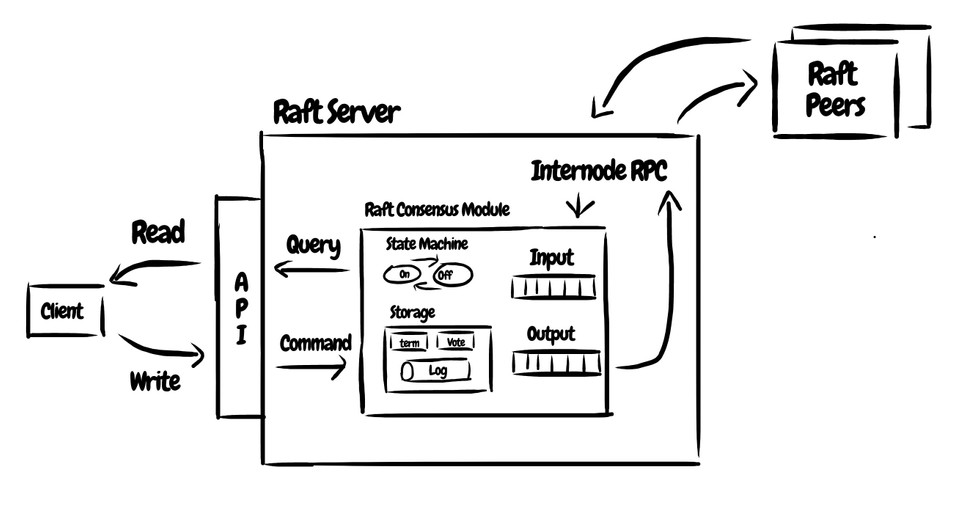
This project showcases my expertise in distributed systems concepts like consensus algorithms, replication, and persistence. The fault-tolerant key-value store provides strong consistency guarantees, high availability through redundancy, and horizontal scalability to handle large workloads. The service is designed to gracefully handle failures and retries with no downtime or data loss.